1. 引言:Java 意外的机器学习复兴
尽管 Python 主导了机器学习的研究与实验,但生产部署讲述着不同的故事。截至 2025 年,68% 的应用程序运行在 Java 或 JVM 上,那些已在 Java 生态系统投入巨资的企业面临一个关键问题:是重新培训团队并重写系统,还是将机器学习能力引入 Java?答案正日益倾向于后者。

Netflix 使用 Deep Java Library 进行分布式深度学习实时推理,通过字符级 CNN 和通用句子编码器模型处理日志数据,每个事件的延迟为 7 毫秒。这代表了一个更广泛的趋势——尽管 Python 在训练方面占主导地位,但 Java 在生产系统、多线程、稳定性和企业集成方面的优势,使其在机器学习部署上极具吸引力。
本文探讨 Java 在机器学习生命周期中的角色,比较各种框架,探索与 Python 生态系统的集成模式,并识别 Java 提供明显优势的场景。
2. Java ML 框架对比
2.1 Deep Java Library:引擎无关的方案
Deep Java Library 是一个开源的、高层次的、引擎无关的 Java 深度学习框架,它提供原生 Java 开发体验,功能如同任何其他常规 Java 库。由 AWS 创建的 DJL,其架构理念以抽象为核心——开发者编写一次代码,即可在 PyTorch、TensorFlow、MXNet 或 ONNX Runtime 之间切换而无需修改。
该框架由五层架构组成。高层 API 层提供符合 Java 习惯的接口,供开发者直接交互。引擎抽象层与底层框架通信,隐藏实现差异。NDManager 管理表示张量的 NDArray 的生命周期,在处理后自动释放张量内存以防止泄漏或崩溃。数据处理层提供为模型准备数据的实用工具。最后,原生引擎层通过对 C++ 实现的 JNA 调用执行实际计算。
DJL 与 TensorFlow、PyTorch、MXNet 等各种深度学习框架无缝集成,提供一个高层次 API 以便于在 Java 环境中轻松构建、训练和部署模型,并且与 AWS 服务紧密集成。其 Model Zoo 提供了来自 GluonCV、HuggingFace、TorchHub 和 Keras 的 70 多个预训练模型,支持单行命令加载模型。
优势:
- 引擎灵活性:允许根据部署需求切换后端(研究模型用 PyTorch,生产用 MXNet,跨平台用 ONNX)。
- 原生多线程支持:与 Akka、Akka Streams 及并发 Java 应用程序自然集成。
- 自动 CPU/GPU 检测:无需配置即可确保最佳硬件利用率。
- 通过 DJL Spring starters 集成 Spring Boot:简化企业采用。
局限:
- 训练功能存在,但不如推理功能成熟。
- 文档侧重于推理而非训练工作流。
- 社区规模小于 Python 优先的框架。
2.2 Deeplearning4j:JVM 原生解决方案
Eclipse Deeplearning4j 是为 Java 虚拟机编写的编程库,是一个广泛支持深度学习算法的框架,包括受限玻尔兹曼机、深度信念网络、深度自动编码器、堆叠降噪自动编码器、递归神经张量网络、word2vec、doc2vec 和 GloVe 的实现。
DL4J 于 2014 年问世,目标客户是已投入 Java 基础设施的企业。Eclipse Deeplearning4j 项目包括 Samediff(一个类似 TensorFlow/PyTorch 的框架,用于执行复杂计算图)、Python4j(一个 Python 脚本执行框架,用于将 Python 脚本部署到生产环境)、Apache Spark 集成以及 Datavec(一个将原始输入数据转换为张量的数据转换库)。
该框架的分布式计算能力使其区别于其他方案。Deeplearning4j 包含与 Apache Hadoop 和 Spark 集成的分布式并行版本。对于处理大规模数据的组织,DL4J 提供了无需 Python 依赖的原生 JVM 解决方案。
优势:
- 完整的 ML 生命周期支持——训练、推理和部署完全在 Java 中完成。
- 分布式训练:使用 Spark 或 Hadoop 在集群中扩展。
- ND4J 提供支持 GPU 加速的、类似 NumPy 的 n 维数组。
- SameDiff 提供类似 TensorFlow 的“先定义后运行”图执行方式。
- Keras 模型导入:支持 h5 文件,包括 tf.keras 模型。
局限:
- 文档和社区资源落后于 TensorFlow 和 PyTorch。
- 与高层次框架相比学习曲线更陡峭。
- 采用范围较窄,主要集中在重度使用 Java 的企业。
2.3 TensorFlow Java:官方但功能有限
TensorFlow Java 可在任何 JVM 上运行以构建、训练和部署机器学习模型,支持 CPU 和 GPU 在图模式或即时执行模式下的运行,并提供了在 JVM 环境中使用 TensorFlow 的丰富 API。作为 TensorFlow 的官方 Java 绑定,它提供了对 TensorFlow 计算图执行的直接访问。
TensorFlow 的 Java 语言绑定已移至其独立的代码库,以便独立于官方 TensorFlow 版本进行演进和发布,大多数构建任务已从 Bazel 迁移到 Maven。这种分离允许在不等待 TensorFlow 核心发布的情况下进行 Java 特定的改进。
优势:
- 与 TensorFlow 生态系统和工具直接集成。
- SavedModel 格式兼容性支持从 Python 到 Java 的无缝模型移交。
- TensorFlow Lite 支持面向移动和边缘部署。
- 通过原生 TensorFlow 运行时支持 GPU 和 TPU 加速。
局限:
- TensorFlow Java API 不在 TensorFlow API 稳定性保证范围内。
- 对 Keras on Java 几乎无官方支持,迫使开发者必须在 Python 中定义和训练复杂模型以供后续导入 Java。
- 与 DJL 甚至 DL4J 相比,较低级别的 API 需要编写更多代码。
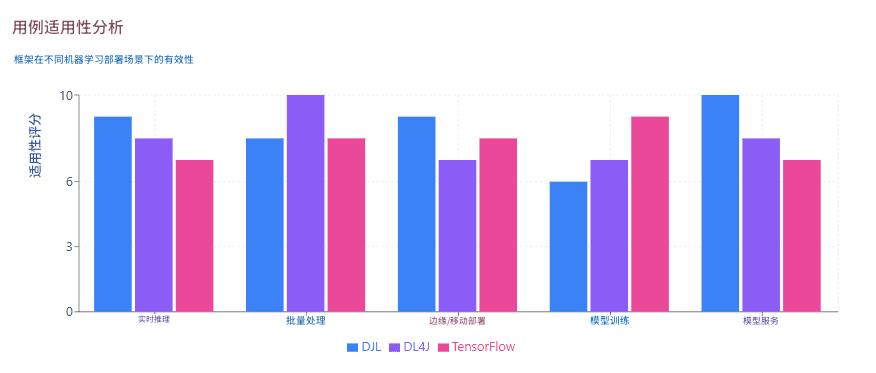
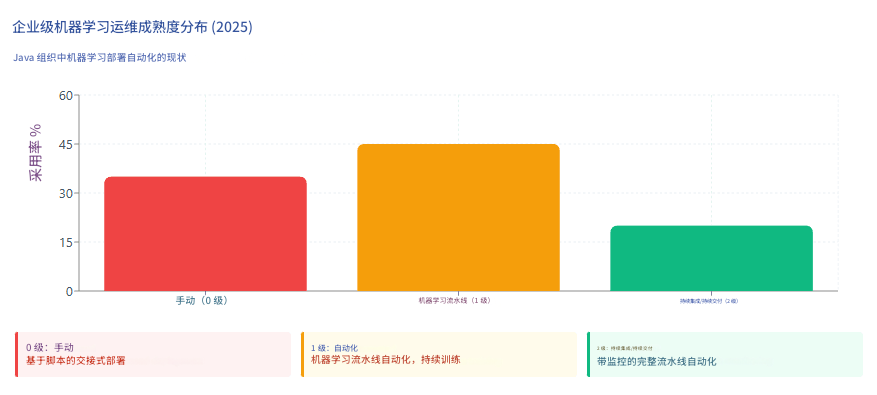
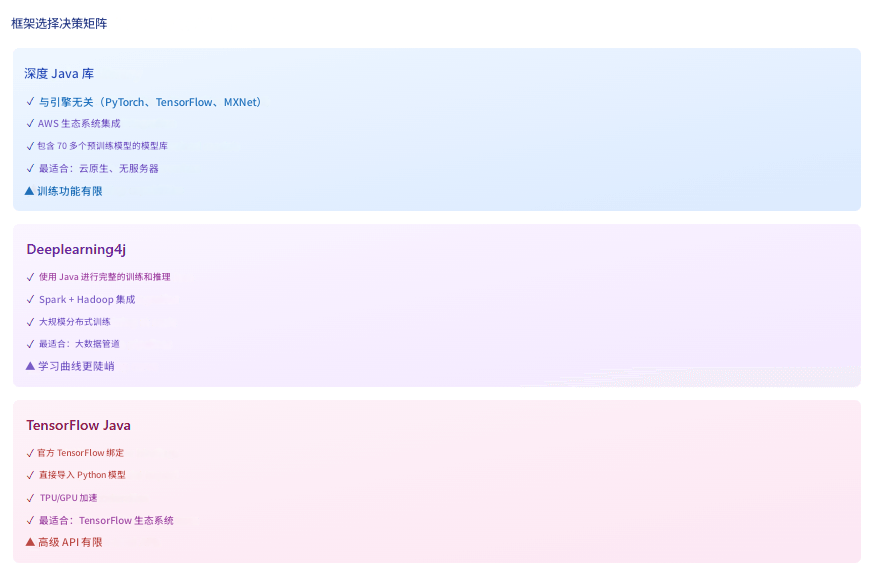
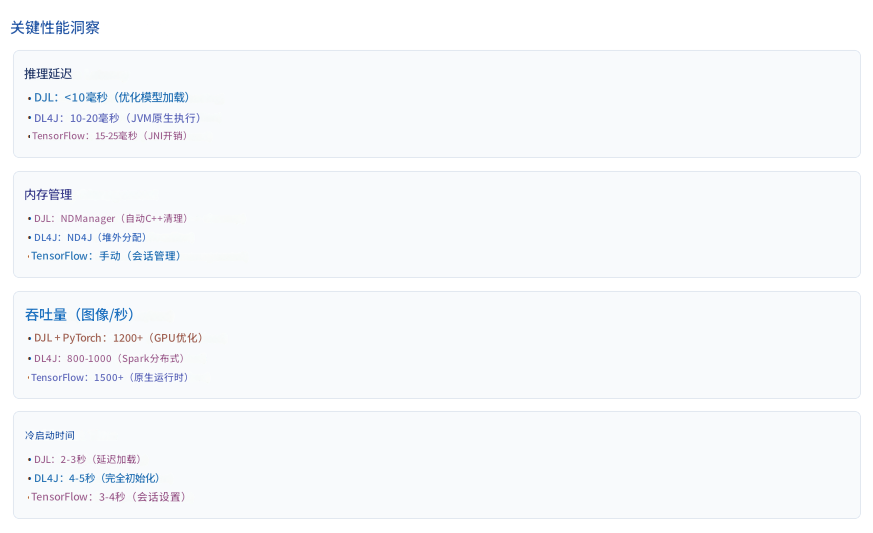
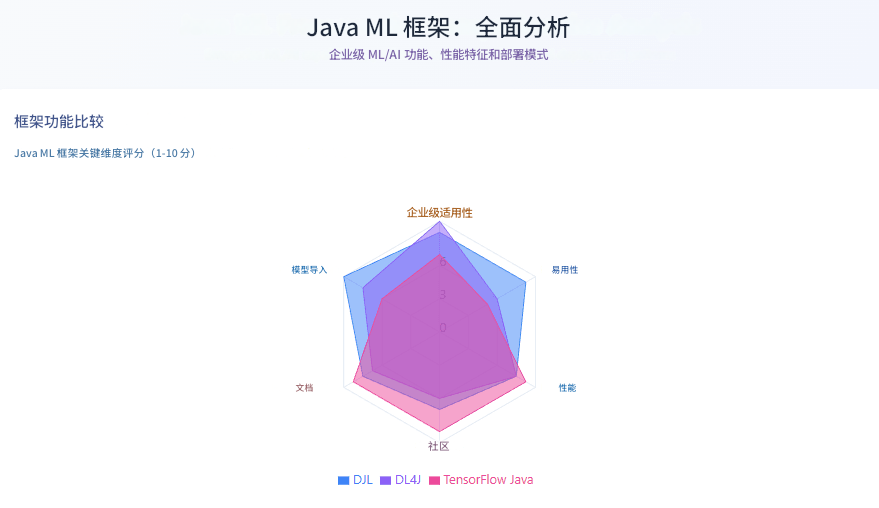
3. 框架对比表
| 标准 | Deep Java Library | Deeplearning4j | TensorFlow Java |
|---|---|---|---|
| 主要用例 | 推理与模型服务 | 完整 ML 生命周期 | 模型服务 |
| 引擎支持 | PyTorch, TensorFlow, MXNet, ONNX | 原生 JVM | 仅 TensorFlow |
| 训练能力 | 有限 | 完全支持 | 有限 |
| 分布式计算 | 通过引擎(如 MXNet 上的 Spark) | 原生 Spark/Hadoop | 通过 TensorFlow |
| 模型导入 | PyTorch, TensorFlow, Keras, ONNX | Keras, TensorFlow, ONNX | 仅 TensorFlow |
| 预训练模型 | Model Zoo 中 70+ | 社区模型 | TensorFlow Hub |
| Spring Boot 集成 | 原生 starters | 手动 | 手动 |
| 学习曲线 | 低 | 中-高 | 中 |
| 内存管理 | NDManager(自动) | ND4J(堆外) | 手动会话 |
| 企业就绪度 | 高 | 非常高 | 中 |
| 社区规模 | 增长中 | 小众 | 大(Python) |
| 最适合 | 云原生推理 | 大数据 ML 流水线 | TensorFlow 生态系统 |
决策矩阵:
- 选择 DJL 用于:微服务、无服务器函数、Spring Boot 应用、引擎灵活性、AWS 生态系统。
- 选择 DL4J 用于:分布式训练、Spark/Hadoop 集成、完整的纯 Java 技术栈、企业数据流水线。
- 选择 TensorFlow Java 用于:现有的 TensorFlow 投资、TPU 部署、直接的 Python 模型兼容性。
4. 与 Python ML 生态系统的集成
4.1 多语言生产模式
最优的企业 ML 工作流通常结合 Python 的研究能力和 Java 的生产优势。数据科学家在熟悉的 Python 环境中使用 TensorFlow、PyTorch 或 scikit-learn 训练模型。工程师随后将这些模型部署在每天处理数百万请求的 Java 应用程序中。
模型导出格式:
- ONNX:这个通用的交换格式支持大多数框架。在 PyTorch 中训练,导出到 ONNX,通过 DJL 或 DL4J 导入。这种方法支持与框架无关的部署流水线。
- TensorFlow SavedModel:对于长期生产服务,导出到中立格式(如 ONNX)或针对服务优化的框架特定生产格式(SavedModel、TorchScript)。SavedModel 将计算图、变量值和元数据打包到单个目录结构中。
- TorchScript:PyTorch 模型通过脚本或追踪序列化为 TorchScript。DJL 的 PyTorch 引擎直接加载这些模型,保持完整的计算图。
- Keras H5:DL4J 导入 Keras 模型(包括 tf.keras 变体),保留层配置和训练好的权重。
4.2 Python4j:在 Java 中嵌入 Python
DL4J 的 Python4j 模块解决了需要 Java 中不可用的 Python 库的场景。Python4j 是一个 Python 脚本执行框架,简化了将 Python 脚本部署到生产环境的过程。该方法将 CPython 解释器嵌入到 JVM 进程中,实现双向调用。
用例包括:
- 在 Java 推理前使用 scikit-learn 流水线进行预处理。
- 从 Java 数据流水线调用专门的 Python 库(NumPy, SciPy)。
- 在 Java 模型服务旁边运行基于 Python 的特征工程。
权衡之处在于需要管理 Python 运行时依赖项和潜在的 GIL 限制。对于高吞吐量场景,模型导出仍然优于运行时 Python 执行。
5. 模型服务与部署模式
5.1 实时推理架构
面向用户的应用,其生产 ML 系统需要低于 100 毫秒的延迟。Java 的线程模型和 JVM 优化在此背景下表现出色。在生产中无需 Python 即可提供 TensorFlow 模型服务,每次预测延迟低于 10 毫秒,并像任何 Spring Boot 服务一样水平扩展。
同步 REST API:
@RestController
public class PredictionController {
private final Predictor<Image, Classifications> predictor;
@PostMapping("/predict")
public Classifications predict(@RequestBody Image image) {
return predictor.predict(image); // <10ms 典型延迟
}
}Spring Boot 的自动配置、健康检查和指标与 DJL 或 DL4J 的预测器实例无缝集成。水平扩展遵循标准的微服务模式——在负载均衡器后部署多个实例。
异步处理:
对于非关键预测,异步处理可提高吞吐量。Java 的 CompletableFuture、Reactor 或 Kotlin 协程支持并发预测批处理:
// 异步批量预测
List<CompletableFuture<Result>> futures = images.stream()
.map(img -> CompletableFuture.supplyAsync(
() -> predictor.predict(img), executor))
.collect(Collectors.toList());5.2 批量推理模式
批量作业可以容器化并部署到作业调度器或流水线(如 Airflow/Prefect、Kubeflow Pipelines、云数据管道服务),而在线模型则部署到服务基础设施(Web 服务器、Kubernetes)。
DL4J 的 Spark 集成处理海量数据集:
// Spark 上的分布式批量评分
JavaRDD<DataSet> testData = loadTestData();
JavaRDD<INDArray> predictions = SparkDl4jMultiLayer
.predict(model, testData);该模式将推理分布在集群节点上,高效处理数百万条记录。对于拥有 Hadoop 或 Spark 基础设施的组织,这种原生集成消除了 Python 桥接开销。
5.3 边缘与移动端部署
DJL 支持部署到边缘设备和移动平台。对于 Android,DJL 提供了针对 ARM 处理器优化的 TensorFlow Lite 和 ONNX Runtime 引擎。自动 CPU/GPU 检测可适应可用硬件。
用例包括:
- 移动应用中的设备端图像分类。
- 无需云连接的 IoT 传感器异常检测。
- 需要本地推理的边缘计算场景。
该方法降低了延迟,提高了隐私性(数据保留在本地),并消除了网络依赖。
6. 可扩展性考量
6.1 容器化与编排
使用 Docker 进行容器化,允许将模型及其代码连同所有必需的库和依赖项打包到一个自包含的单元中,该单元可以在任何地方运行(您的笔记本电脑、云虚拟机、Kubernetes 集群中)。
Java ML 服务与传统 Spring Boot 应用的容器化方式相同:
Dockerfile 模式:
FROM eclipse-temurin:21-jre-alpine
COPY target/ml-service.jar app.jar
ENTRYPOINT ["java", "-jar", "app.jar"]Kubernetes 编排处理扩展、健康检查和滚动更新。这种统一性意味着现有的 DevOps 流水线无需特殊处理即可扩展到 ML 服务。
6.2 性能优化策略
- 模型量化:通过将 float32 权重转换为 int8 来减少模型大小和推理时间。TensorFlow Lite 和 ONNX Runtime 支持量化,且精度损失最小。典型收益:模型缩小 4 倍,推理速度加快 2-3 倍。
- 批处理:将预测分组以分摊开销。DJL 和 DL4J 支持批处理输入,利用 SIMD 指令,并将每项预测的延迟从 10 毫秒降低到批量 32 条时的每条 2-3 毫秒。
- 模型编译:ONNX Runtime 和 TensorFlow XLA 将模型编译为优化的执行图。在容器构建期间进行预编译可消除运行时编译开销。
- 内存管理:DJL 通过其特殊的内存收集器 NDManager 解决了内存泄漏问题,该管理器及时收集 C++ 应用程序内部的陈旧对象,在测试 100 小时连续推理不崩溃后,在生产环境中提供稳定性。
- 连接池:对于调用外部模型服务器(TensorFlow Serving、Triton)的服务,维护连接池以减少 TCP 握手开销。
6.3 水平扩展模式
Java ML 服务的扩展方式与无状态 Web 服务相同:
- 在负载均衡器后部署多个实例。
- 基于 CPU、内存或自定义指标(推理队列深度)使用 Kubernetes HorizontalPodAutoscaler。
- 实施熔断器以优雅地处理下游故障。
- 使用 Redis 或 Caffeine 缓存频繁的预测结果。
推理的无状态特性(给定模型版本)使得无需协调开销即可实现弹性扩展。
7. Java 应用的 MLOps
7.1 持续训练与部署
MLOps 团队的目标是自动将 ML 模型部署到核心软件系统中或作为服务组件,自动化整个 ML 工作流步骤,无需任何人工干预。
- Level 0(手动):许多团队拥有能够构建先进模型的数据科学家和 ML 研究人员,但他们构建和部署 ML 模型的过程完全是手动的,每个步骤都需要手动执行和手动过渡。这代表了 2025 年 35% 的 Java ML 部署。
- Level 1(ML 流水线自动化):自动化训练流水线根据新数据重新训练模型。Jenkins、GitHub Actions 或 GitLab CI 触发训练作业,将模型导出到工件仓库(Nexus、Artifactory),并通知部署系统。版本化的模型自动部署到预发布环境。
- Level 2(ML 的 CI/CD):持续集成通过添加测试和验证数据和模型来扩展对代码和组件的测试和验证;持续交付关注自动部署另一个 ML 模型预测服务的 ML 训练流水线的交付;持续训练自动重新训练 ML 模型以重新部署。
在 Java 上下文中,这意味着:
- 数据流水线和预处理的自动化单元测试。
- 确保模型预测符合预期输出的集成测试。
- 金丝雀部署(5% 流量导向新模型版本)。
- 性能下降时的自动化回滚。
7.2 模型版本控制与注册
将模型视为一等工件:
models/
fraud-detection/
v1.0.0/
model.onnx
metadata.json
v1.1.0/
model.onnx
metadata.json元数据包括训练日期、数据集版本、性能指标(准确率、F1 分数)和依赖版本。可以使用 Maven 坐标引用模型版本:
<dependency>
<groupId>com.company.ml</groupId>
<artifactId>fraud-detection-model</artifactId>
<version>1.1.0</version>
<classifier>onnx</classifier>
</dependency>这种方法将标准的依赖管理实践应用于 ML 模型,从而实现可重复的构建和可审计的部署。
7.3 监控与可观察性
ML 模型部署后,需要进行监控以确保其按预期执行。Java 的可观察性生态系统自然地扩展到 ML 服务:
要跟踪的指标:
- 推理延迟:通过 Micrometer 统计 p50、p95、p99 百分位数。
- 吞吐量:每秒预测数、每秒请求数。
- 错误率:失败的预测、模型加载失败。
- 数据漂移:通过统计测试检测到的输入分布变化。
- 模型性能:生产数据上的准确率、精确率、召回率(当标签可用时)。
与现有工具的集成:
Spring Boot Actuator 暴露 ML 特定指标:
@Component
public class PredictionMetrics {
private final MeterRegistry registry;
public void recordPrediction(long latencyMs, String modelVersion) {
registry.timer("prediction.latency",
"model", modelVersion)
.record(Duration.ofMillis(latencyMs));
}
}Prometheus 抓取这些指标,Grafana 可视化趋势,并在出现异常(延迟峰值、准确率下降)时触发告警。
7.4 测试 ML 系统
- 单元测试:验证数据预处理、特征工程和后处理逻辑。标准的 JUnit 测试即可满足。
- 集成测试:测试 ML 模型是否成功加载到生产服务中,并且对真实数据的预测符合预期;测试训练环境中的模型与服务环境中的模型给出相同的分数。
- 性能测试:使用 JMeter 或 Gatling 模拟负载,在真实流量模式下测量吞吐量和延迟。建立基线并检测回归。
- 影子部署:将新模型版本与现有版本并行运行,记录预测而不影响用户。在全面部署前比较结果以识别意外行为。
8. Java 在机器学习中表现出色的用例
8.1 企业集成场景
- 金融服务中的欺诈检测:拥有成熟 Java 生态系统的企业越来越寻求将 ML/AI 模型直接集成到其后端系统的方法,而无需启动单独的基于 Python 的微服务。银行每天通过 Java 系统处理数百万笔交易。将 DJL 预测器直接嵌入交易处理流水线中,无需外部服务调用即可实现低于 10 毫秒的欺诈评分。
- 实时推荐:基于 Spring Boot 构建的电子商务平台集成 DJL 进行产品推荐。会话数据流经现有的 Java 服务,预测在进程内进行,结果无需网络延迟即可呈现。
- 日志分析与聚类:Netflix 的可观察性团队使用 DJL 在生产中部署迁移学习模型,以对应用程序日志数据进行实时聚类和分析,通过字符级 CNN 和通用句子编码器模型处理日志行,每条约 7 毫秒。基于 DJL 的流水线分配保留相似性的聚类 ID,从而实现告警量减少和存储效率提高。
8.2 大数据 ML 工作流
使用 Spark 或 Hadoop 每天处理 TB 级数据的组织受益于 DL4J 的原生集成。在历史数据上训练模型、对新记录进行评分以及更新模型——所有这些都在 Spark 流水线内完成,无需 Python 桥接。
示例工作流:
- 从 HDFS 或 S3 将数据读入 Spark DataFrames。
- 使用 Spark SQL 进行特征工程。
- 在集群上分布式训练 DL4J 模型。
- 使用训练好的模型对新数据评分。
- 将结果写回数据仓库。
整个端到端流程保持在 JVM 中,避免了序列化开销和 Python 互操作的复杂性。
8.3 微服务与云原生应用
Spring Boot 应用程序主导着企业微服务架构。通过 DJL starters 添加 ML 能力可无缝集成:
- 熔断器:Resilience4j 模式保护 ML 服务免受级联故障影响。
- 服务发现:Eureka 或 Consul 注册 ML 预测服务。
- 配置:Spring Cloud Config 管理模型端点和参数。
- 追踪:Zipkin 或 Jaeger 追踪通过 ML 流水线的请求。
这种统一性简化了运维——ML 服务与业务逻辑服务以相同的方式部署、扩展和监控。
8.4 边缘计算与物联网
Java 的“一次编写,随处运行”理念扩展到边缘设备。为 ARM 处理器编译的 DJL 模型可以在 Raspberry Pi、NVIDIA Jetson 和工业 IoT 网关上运行。用例包括:
- 预测性维护:本地分析传感器数据,异常时触发警报。
- 视频分析:在边缘处理安防摄像头视频流,减少带宽。
- 智能家居设备:设备端语音识别和自然语言理解。
GraalVM 原生镜像编译生成独立的可执行文件,内存占用小(< 50MB),启动速度快(< 100ms),非常适合资源受限的环境。
8.5 法规与合规要求
随着欧盟《人工智能法案》等法规的收紧,集成重点转向模型的左移安全性——在流水线中扫描偏见、可解释性和合规性。Java 的强类型、显式异常处理和成熟的日志记录框架便于审计追踪和满足可解释性要求。
金融和医疗保健行业通常要求所有代码(包括 ML 模型)通过经过验证的、带有审批工作流的流水线进行部署。与引入 Python 运行时依赖相比,Java ML 服务能更自然地与现有的治理流程集成。
9. 结论:我们的收获
Java 在机器学习中的作用代表了务实的生产工程,而非研究创新。我们分析得出的主要见解:
- 框架选择取决于上下文:DJL 在推理和模型服务方面表现出色,具有引擎灵活性,是云原生微服务的理想选择。DL4J 提供了与大数据框架集成的完整 ML 生命周期功能,适用于需要分布式培训的组织。TensorFlow Java 服务于深度投入 TensorFlow 生态系统、需要直接模型兼容性的团队。
- 多语言模式行之有效:在 Python 中训练并在 Java 中部署,利用了每种语言的优势。ONNX 和 SavedModel 格式支持无缝交接。Python4j 在必要时弥合差距,但出于性能考虑,模型导出仍是首选。
- 生产性能至关重要:Netflix 7 毫秒的推理延迟证明 Java ML 服务能够满足实时性能要求。适当的内存管理(NDManager、ND4J)、模型优化(量化、编译)和水平扩展提供了生产级系统。
- MLOps 成熟度参差不齐:只有 20% 的 Java ML 部署达到了 Level 2 CI/CD 成熟度,具备自动重新训练和监控。机会在于将已建立的 DevOps 实践——容器、编排、可观察性——应用于 ML 工作流。
- Java 在特定场景中表现出色:企业集成(欺诈检测、推荐)、大数据 ML 流水线(Spark/Hadoop)、微服务架构、边缘计算和法规合规代表了 Java 的特性——稳定性、线程处理、生态系统成熟度——相比以 Python 为中心的方法提供优势的领域。
- 内存管理区分了框架:DJL 的 NDManager 解决了管理 JVM 应用程序中本机内存的关键挑战,实现了 100 小时以上的生产运行而无内存泄漏。这种生产就绪性将企业可行的框架与实验性绑定区分开来。
- 差距正在缩小:虽然 Java 不会取代 Python 在 ML 研究中的地位,但像 DJL 和 DL4J 这样的框架已经足够成熟,可用于生产部署。生态系统现在支持完整的推理生命周期,性能可与 Python 解决方案相媲美。
未来可能涉及更深层次的集成——Spring AI 为 Java 带来 LLM 能力,GraalVM 原生镜像为无服务器 ML 实现即时启动,以及 MLOps 和 DevOps 实践之间持续的融合。对于拥有大量 Java 投资的组织,问题从“我们能用 Java 做 ML 吗?”转变为“我们如何优化 Java ML 部署?”。
随着 ML 在企业系统中变得无处不在,Java 的生产优势——稳定性、性能、工具成熟度和操作熟悉度——使其成为推理层的务实选择,即使 Python 在训练和实验中仍占主导地位。多语言方法——在 Python 中训练,在 Java 中部署——代表的不是妥协,而是对每个平台独特优势的优化。
【注】本文译自:AI and Machine Learning in Java: TensorFlow, DJL, and Enterprise AI