第1章 理解领域驱动设计
引言
软件已成为业务成功不可或缺的战略要素,渗透到现代组织的各个层面。企业日益依赖技术来提升效率、交付价值并保持竞争力。这种日益增长的依赖性凸显了能够使软件解决方案与业务目标紧密契合的开发实践的重要性。领域驱动设计【Domain-driven design (DDD)】 应运而生,正是为了满足这一需求,它提供了一种直接的方法来弥合业务期望与技术实现之间长期存在的鸿沟。它使团队交付的软件,能精准、清晰且持续地支撑和驱动业务成果。
随着商业环境变得更加动态和多面化,将领域知识转化为有效软件解决方案的挑战日益凸显。一个常见的问题在于相关方的设想与软件最终交付成果之间的错位。行业观察指出许多软件项目的关键失败点在于:过度关注未经验证的计划和设计、客户期望模糊或不断变化、实施过程中出现不可预见的复杂性,以及产品与工程团队之间协作不力。这些问题常常导致技术工作严重偏离业务目标。
在当前工具生态中,选择的悖论进一步加剧了这种脱节。尽管开发团队可以接触到前所未有的丰富框架和技术,但过多的选择可能导致决策瘫痪、效率低下,并使人忽视真正重要的东西。在此背景下,复杂性成为一种负担而非优势,使得在整个开发过程中保持清晰度和业务对齐变得越来越困难。
这正是DDD实践发挥其作用之处。通过将开发工作立足于业务领域,并鼓励有意的协作建模,DDD提供了一个交付能反映相关方真实需求解决方案的框架。DDD并不规定特定的架构或技术栈,而是倡导清晰性、共同理解和长期可维护性,而不受技术约束的限制。
本章介绍了DDD背后的基本原理,解释了它为何重要以及它旨在解决哪些问题。它为后续更深层次的技术和战略主题奠定了基础。掌握DDD不仅仅是学习模式——它始于理解其原则,特别是指导从发现到实施的战略和战术维度。本章是这段旅程的第一步。
结构
在本章中,我们将探讨以下主题:
- 领域驱动设计的重要性
- 连接业务目标与技术实现
- 核心概念与方法论
学习目标
本章旨在为理解DDD在软件开发中为何至关重要奠定基础,重点关注那些常导致项目失败的挑战,例如业务与技术团队之间的错位、不明确的客户期望以及不必要的复杂性。通过探讨DDD的原则,本章展示了它如何提供一种结构化方法来弥合业务与技术之间的差距,促进协作,并确保软件解决方案与现实需求保持一致。本章不深入探讨实现细节,而是介绍DDD背后的逻辑,为全书深入讨论其战略和战术应用做好铺垫。
领域驱动设计的重要性
DDD能够通过以下方式应对常常导致软件项目脱轨的常见挑战:
- 对齐业务与技术团队:DDD提出的实践可以澄清业务需求,并确保技术实现满足这些需求和期望。
- 澄清客户期望:减少误解和模糊的需求,从而产生真正满足相关方目标的软件。
- 简化解决方案设计:将系统的复杂性分解为可管理的部分,可以减少常常令人难以招致、拖慢进度并使长期维护变得困难的复杂性。通过掌握正确的实践,团队可以从更简单的设计中受益,从而降低软件维护的难度。
- 改善跨团队协作:当业务和技术团队不能紧密合作时,关键的商业见解可能在沟通过程中丢失。借助DDD,每个人都可以协作并开始朝着相同的目标努力。
通过将软件开发建立在业务领域的基础上,并促进技术团队与业务团队之间持续紧密的合作,DDD实践可以使您的团队确保每个类、方法和变量都与核心业务需求正确对齐,最终让您能够控制最终产品的价值及其与相关方期望的一致性。
DDD最显著的优势之一是其管理复杂性的能力。在软件开发工具和框架数量不断增长的世界里,开发人员迟早会感到选择过多而迷失业务目标。DDD通过一种结构化方法来应对,该方法允许将复杂的业务领域分解为可管理且重点突出的子域。这样,软件变得更容易理解和维护,同时确保开发过程与整体业务战略保持一致。
此外,DDD强调通用语言的重要性,这是业务和技术团队之间一致使用的共享语言。共同的词汇可以最大限度地减少误解,并驱动项目所有参与者朝着相同的目标努力。开发过程转变为一种协作的跨团队努力,业务和IT部门可以共同创建并交付能够准确反映业务需求和目标的解决方案。
现在,着眼于DDD在现实场景中的实际应用,我们可以参考那些精确性和团队对齐至关重要的行业。例如,在合规性和准确性至上的银行业,DDD确保贷款管理系统和交易平台的设计既满足法规要求,也满足金融专业人士的特定需求。在电子商务领域,DDD使得能够开发出快速适应不断变化的市场需求,同时保持无缝客户体验的平台。
最终,DDD的重要性在于它能为软件开发过程带来清晰度和专注度。通过确保软件反映并支持业务的战略目标,DDD提高了解决方案的整体质量和商业价值。了解您工作所交付的价值,可以激励您在自己的项目中有效地实施DDD。在下一节中,让我们探讨DDD如何帮助弥合业务与技术团队之间的鸿沟,为您提供能够改善项目中跨团队协作的基础知识。连接业务目标与技术实现
软件开发中最大的挑战之一是业务目标与技术实现之间的差距。这种差距常常导致误解、优先级冲突以及软件未能达到目标。DDD可以通过将领域专家融入开发过程来克服这一挑战。
DDD的核心思想是让软件开发与其所支持的业务领域紧密对齐。开发人员不是依赖大量描述需求的文档,而是可以直接与业务专家(又称领域专家)合作,从而直接了解业务的核心活动、挑战和目标。这种紧密合作是一项关键实践,它使领域专家能够为更好、更明智的技术决策提供关键见解。
弥合沟通鸿沟的一个关键方法是使用通用语言,即两个团队共享的词汇表。在协作中,团队定义并商定这些术语,随后这些术语在项目各阶段(从初始讨论到实施、验证及最终交付)持续一致地使用。这种方法可以最大限度地减少误解,通过减少错误和不符合要求的不正确交付来节省时间。
DDD还鼓励团队围绕业务领域构建软件系统,通过以反映业务本身结构的方式来设计代码。这种方法使软件更直观、更易于维护,简化了行业中可能的变化在软件中的反映。
通过运用DDD实践来弥合业务与技术之间的分歧,可以使组织能够创建技术上良好且与企业战略目标紧密对齐的软件。因此,可以创建出更有效、更高效、更有价值并为业务带来切实效益的软件解决方案。
在本章的下一节中,我们将分解DDD的核心概念和方法论,让您更好地理解如何将理论应用到您的软件项目中。核心概念和方法论
在深入探讨DDD之前,我们必须首先分解其主要概念及其含义。
领域是指我们旨在转化为代码的特定主题或知识领域。领域的大小或复杂性不是问题,因为我们可以应用分治法将复杂领域分解为更小、更易于理解的子集。
下图说明了软件开发中的这种分治方法。它直观地展示了软件开发中的知识如何分解为不同的领域,如数据库、文档和架构,并进一步细分为像SQL和NoSQL这样的子域。这种可视化分解有助于阐明DDD如何通过专注于特定的业务领域来鼓励理解和管理复杂性。
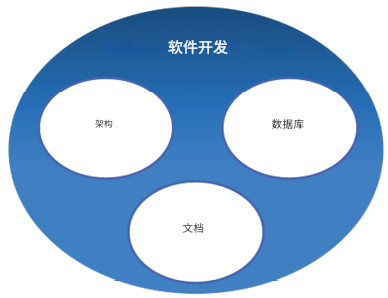
图1.1:软件开发作为一个领域
在DDD的语境中,业务领域是公司主要的活动领域,反映其核心提供的价值。例如,星巴克主要与咖啡相关,而亚马逊则在零售和云计算等多个领域运营。公司可以发展,随时间改变或扩展其业务领域。
为了管理领域的复杂性,可以将其细分为子域。这些子域可以进一步分为核心子域、支撑子域和通用子域。
鉴于软件工程师对客户业务知识有限,领域专家扮演着至关重要的角色。领域专家对业务复杂性有深刻理解,这些细节自然地成为其软件中的需求。
注:最后的术语"设计"可能难以定义,常常与软件架构混淆。《软件架构基础》等经典著作将架构描述为那些难以更改的东西或设计,但这仍然是一个抽象概念,因为难以更改的内容会有所不同。Neal Ford的著作《Head First in Software Architecture》提供了更细致的观点,将架构和设计定义在一个光谱上,设计是关于做出决策来塑造软件系统的结构和组织,以管理复杂性并创建连贯、可维护的架构。
下图展示了从软件架构到设计的决策光谱。它表示了设计与架构之间的紧密联系,以及设计决策如何可以是一个更轻松的定义,或者如何成为软件系统核心结构的内在部分。
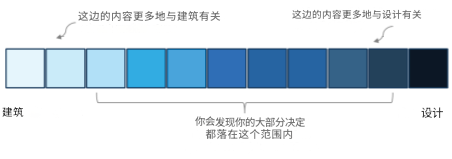
图1.2:架构与设计的光谱
考虑到这一点,我们可以将DDD定义为对软件系统结构和组织做出的有意决策,旨在提取业务知识并将其转化为代码。
DDD是语言无关的,可以用于任何编程语言、范式或框架构建的解决方案。虽然通常与面向对象编程和Java相关联,但DDD实践也适合根据项目需求选择的任何其他语言。
提示:本书并非旨在取代关于DDD的经典文献,而是通过实践指导来补充它。像Eric Evans的《领域驱动设计:软件核心复杂性应对之道》和Vaughn Vernon的《实现领域驱动设计》这样的基础著作是必读的,即使它们看起来具有挑战性。
DDD有两个主要组成部分:战略和战术。两者对于确保良好的技术质量和正确的业务对齐都至关重要。让我们探讨这两个方面的区别以及它们如何相互作用。DDD的战略层面
DDD是所有开发工作建立的基础,其重点是加深对业务、其核心领域以及共同构成其运营的子域的理解。
DDD中的战略着眼于大局,识别业务中最关键、应优先考虑并反映在软件中的领域。这不仅需要协作,更需要与领域专家建立伙伴关系,他们能够传达系统中需要捕捉的复杂性。战略方法使得开发过程中的每个决策都能基于对业务背景扎实、透彻的理解。它指导整个软件项目的结构和方向。DDD的战术层面
DDD的战术层面涉及将战略见解实际应用到代码中。
一旦业务领域和子域被明确定义,并且通用语言(领域的术语和关键概念)建立起来,DDD的战术层面就开始发挥作用。它包括实施特定的设计模式和编码实践,这些能够通过软件将战略愿景变为现实。战术确保软件架构与业务模型保持一致,因为领域的抽象概念被转化为具体的、功能性的系统组件。DDD战略的标准定义通过可操作的任务得到准确体现,例如创建实体、值对象、聚合和仓库。
战略和战术在DDD中结合起来,形成了一种连贯的软件开发方法。这种方法在DDD中不仅是一种选择,更是一种必然。战略提供了总体愿景,并确保软件与业务需求保持一致,而战术则负责将这一愿景转化为可运行系统的实际工作。两者都至关重要;没有坚实的战略基础,软件可能无法充分应对业务的核心挑战;没有有效的战术,即使是最好的战略计划也可能在执行中失败。通过整合这两个方面,DDD使得能够创建技术上健壮且与业务高度相关的软件。
提示:正如《软件设计哲学》中所解释的,战略型软件工程师明白,软件开发不仅仅是编写代码。相反,只关注战术可能弊大于利,从而获得"战术龙卷风"的绰号。
虽然软件工程师很容易对DDD的战术方面感到兴奋,但重要的是要记住,有效的实施必须从战略开始。DDD的目标是提取业务知识并将其编码到软件中,这使得战略成为关键的第一步。在本书中,我们将探讨能够将您的DDD实践提升到新水平的核心战略和战术知识。本章小结
本章解决了确保软件开发满足客户和相关方期望这一根本性挑战。通过探讨DDD的核心原则,我们展示了这种方法如何使软件与业务目标保持一致。我们强调了理解领域、做出有意的设计决策以及成功实施DDD所需的战略基础的关键作用。本章的要点包括:DDD如何确保开发与业务需求之间的对齐、领域和设计在将业务知识转化为软件中的作用,以及业务和技术团队之间协作的重要性。
下一章将深入探讨战略DDD,探索如何有效地识别和分类领域与子域。这种战略洞察将为您提供工具,以做出明智的、与业务对齐的决策,确保您的DDD努力为客户带来真正的价值。
要点总结 - DDD聚焦于业务对齐:DDD的主要目标是确保软件开发与业务目标保持一致并交付真实价值。
- 常见的项目失败源于错位:诸如不明确的客户期望、糟糕的协作以及过于复杂的设计等问题常常导致软件无法满足业务需求。
- 业务领域是DDD的核心:软件应围绕实际的业务领域构建,使用反映现实世界运作的概念和语言。
- 协作是关键:通过共享的通用语言促进业务和技术团队之间的有效沟通,可以减少误解并改善软件成果。
- DDD兼具战略性和战术性:战略方面侧重于理解领域和子域,而战术方面则涉及实施反映业务需求的模式和结构。
- 复杂性应被管理而非增加:DDD有助于将复杂系统分解为可管理的部分,确保软件保持适应性、可维护性并与不断发展的业务需求保持一致。
- 本章为DDD奠定基础:本章并非涵盖所有细节,而是介绍DDD背后的逻辑,为您深入学习其战略和战术应用做好准备。
选择题
- DDD旨在解决的主要挑战是什么?
a. 降低软件开发成本
b. 使软件开发与业务目标保持一致
c. 提高软件交付速度
d. 增加软件项目的技术复杂性
e. 增强软件界面的美学设计 - 以下哪项不是本章讨论的DDD关键焦点?
a. 领域
b. 设计
c. 战术实施
d. 战略基础
e. 美学用户界面设计 - 为什么在DDD中拥有战略基础至关重要?
a. 它有助于降低软件工具的成本。
b. 它确保软件架构难以更改。
c. 它使软件解决方案与业务目标紧密结合。
d. 它只专注于开发的技术方面。
e. 它消除了对领域专家的需求。 - 在DDD中,为什么业务和技术团队之间的协作至关重要?
a. 为了增加项目的复杂性
b. 为了确保软件按时交付
c. 为了促进共同理解和语言,减少不必要的复杂性,并确保软件交付业务真正需要的东西
d. 为了减少所需的技术资源,并在没有额外复杂性的情况下交付业务真正需要的东西
e. 为了让技术团队可以独立做出所有决策 - 领域专家在DDD中的主要角色之一是什么?
a. 为软件编写代码
b. 提供深刻的业务知识以指导开发过程
c. 管理项目的技术资源
d. 设计软件的用户界面
e. 创建详细的软件架构图答案
题号 答案选项 1 b 2 e 3 c 4 d 5 b 参考文献
- Sinek, Simon. Start with Why: How Great Leaders Inspire Everyone to Take Action, 2009.
- McAfee, Andrew. Now Every Company Is A Software Company, Forbes Techonomy, 2011.
- Quidgest. Every Business Is a Software Business, Quidgest Articles, n.d.
- Forbes Technology Council. 16 Obstacles To A Successful Software Project (And How To Avoid Them), Forbes, 2022.
- Schwartz, Barry. The Paradox of Choice: Why More Is Less, 2004.
- Krill, Paul. Complexity Is Killing Software Developers, InfoWorld, 2012.
- Evans, Eric. Domain-Driven Design: Tackling Complexity in the Heart of Software, 2003.
- Vernon, Vaughn. Implementing Domain-Driven Design, 2013.
- Richards, Mark & Ford, Neal. Fundamentals of Software Architecture: An Engineering Approach, 2020.
- Ford, Neal. Software Architecture: The Hard Parts, 2021.
- Ousterhout, John. A Philosophy of Software Design, 2018.
- DDD旨在解决的主要挑战是什么?
加入我们的Discord空间
加入我们的Discord工作区,获取最新更新、优惠、全球科技动态、新版本发布以及与作者的交流机会:https://discord.bpbonline.com